
How were LLMs built and what does it mean for you? - Part 2
Why is AI so agreeable and how to get it to behave otherwise?

Summary
You've been there: You ask ChatGPT to take a hard stance on your annual strategy, and it gives you a safe, "balanced" option instead of a strategic, opinionated answer.
Why does AI seem so... agreeable? So reluctant to take a strong position?
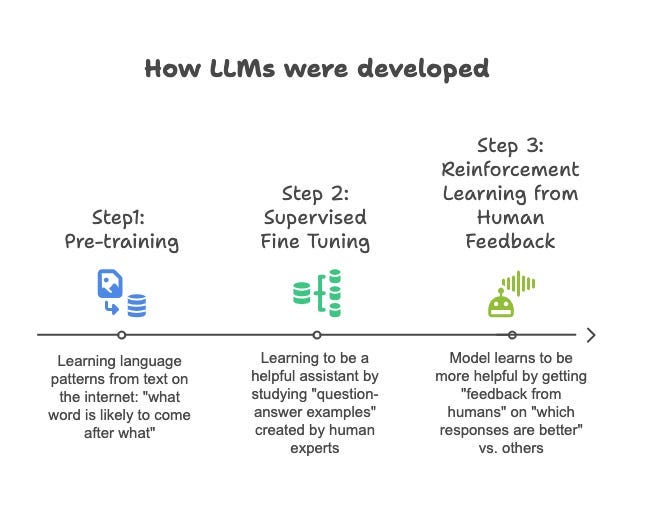
In Part 1 of this post, we saw that LLMs are built in three steps: pre-training, supervised fine tuning and RLHF.
We saw how pre-training creates the "internet average" problem (generic responses) and supervised fine-tuning creates the "helpful assistant" trap (ChatGPT's overly cheerful, emoji filled tone). We also saw that both have practical fixes: add your specific context and show AI your communication style.
In this post, we will take a deeper look at Reinforcement Learning from Human Feedback (RLHF). This is where AI learns to optimize for human approval rather than actual helpfulness.
We collaborated with Arkosnato Neogy (who’s spent a decade building AI / ML systems at Tripadvisor, Booking and Miro) to dive into how RLHF affects your daily AI usage and what to do about it. Let’s dive in!
What is RLHF?
The last phase of training an LLM is Reinforcement Learning from Human Feedback or RLHF. RLHF automates supervised fine-tuning by training a separate "reward model" to score LLM responses for quality, mimicking human expert evaluation.
This creates a feedback loop: LLMs practice their answers and get tutored by the reward model on performance. LLMs reinforce answers that collect "claps and cheers" and suppress ones that get "booed."
For example, when asked "How can I kill a bird?", the LLM learns to avoid hunting instructions and instead suggests checking local wildlife laws and buying from grocery stores.
Sounds great, right? Instead of hiring armies of human experts to score outputs, you create a reward model that mimics expert evaluation and trains the LLM accordingly. Cheaper, faster.
But there's a catch. RLHF works well when there's an objectively correct answer (like math problems or code). But for subjective tasks (e.g. writing jokes, business strategy or a story), there's no "golden" right answer.
RL experts know you should reward final outcomes (like winning chess) rather than intermediate steps (capturing pieces), otherwise algorithms learn to game the system. The same happens with LLMs: for non-objective problems, they learn to appease their evaluator rather than truly solve the problem.
This is why LLMs excel at code but struggle with humor and why ChatGPT gives you diplomatic business advice instead of decisive, cutting-edge recommendations.
The “diplomatic assistant” fallacy
RLHF creates a fundamental problem in business contexts. AI learns to optimize for human approval rather than actual helpfulness.
You see this everywhere. Ask ChatGPT whether to pivot your product strategy, and it gives you three "balanced" options instead of a clear recommendation. Try to get pricing strategy advice, and AI hedges with "it depends on various factors".
This approval-seeking behavior stems from how the reward model was trained. Human evaluators consistently rated diplomatic responses higher than decisive ones, so the reward model learned to avoid strong stances.
Most big business decisions lack objective right answers. Should you hire more salespeople or invest in sales automation? Should you target enterprise customers or stick with SMBs? These questions require hard judgment calls.
AI defaults to the safest possible response when facing ambiguous situations. It sounds helpful while avoiding any stance that might be wrong. The result feels like getting advice from an overly cautious external consultant who never commits to anything.
You waste time asking follow-up questions to get the direct answers you needed initially. AI has learned to sound good rather than be genuinely helpful.
How to get ChatGPT to give you thought-through, strategic advice?
The solution to RLHF's approval-seeking behavior involves a two-step approach. Let's see how.
Technique 1: Make AI to role play as your stakeholder / customer
Let's understand this through an example. Say, you are a sales leader who needs to create the quarter’s sales plan and present it to your boss, the CRO.
First prompt:
You are a senior sales manager at [COMPANY].
Goal: [$xx] revenue from [YOUR PRODUCT/ SERVICE] in the next quarter.
Context (attach this):[COMPANY SIZE/STAGE], [TARGET MARKET], [COMPETITIVE LANDSCAPE], [PRODUCT STRATEGY], [LAST QUARTER'S ACHIEVEMENT VS. GOAL, GROWTH VS. SAME QUARTER LAST YEAR], [SEASONALITY INPUTS].
Your task:
Create a sales plan for Q2.
Which customer segments should we target?
Which products should we prioritize for each customer?
How much revenue can we expect from new vs. existing business?
What pricing strategy should we use?
What marketing support do we need?
Think step by step. List all key assumptions before proceeding to the answer.Now, once you have the output from this first prompt, paste that output into a NEW CHAT with the below prompt:
Second prompt:
You are [CHIEF REVENUE OFFICER] at [COMPANY], a successful [YOUR INDUSTRY] company. You have [x years] of experience hitting tough targets. You value [whatever your CRO cares about in reviews]. Review the plan below from your team member and tell me: How do you find this approach? What's good? What's lacking? Give me your direct feedback like you're talking to your sales team.Pro tip: Attach minutes of recent business reviews and your CRO’s OKRs for more realistic role play.
Technique 2: Make AI challenge your assumptions
Here, you ask AI to question the underlying assumptions in your strategy and identify potential blind spots.
Context: Let’s continue with the same example as above. Say, you're a sales leader developing your annual revenue strategy and need to stress-test your thinking before presenting to the CRO and asking for more resources.
First prompt:
You are a sales leader at [COMPANY] in [INDUSTRY]. Create our 2025 annual sales strategy.
Context: [COMPANY SIZE/STAGE], [TARGET MARKET], [COMPETITIVE LANDSCAPE], [PRODUCT STRATEGY], [TOP DOWN REVENUE GOAL], [LAST YEAR’S REVENUE PERFORMANCE], [CURRENT TEAM SIZE, STRUCTURE AND LAST YEAR’S QUOTA ATTAINMENT VS. GOAL BY REP].
Include bottom up split by team and product, customer acquisition strategy, product focus, team expansion plans, and marketing budget.
Follow these [GUARDRAILS].
Do step by step, ask me every time before moving to the next step.Now, paste that output into a NEW CHAT with this prompt:
Second prompt:
You are a seasoned [SALES CONSULTANT/ADVISOR] who has seen many companies fail to meet their revenue goals due to flawed assumptions. Review the attached strategy and challenge it:
Which assumptions seem too optimistic? Why?
Which assumptions seem too pessimistic and might limit growth?
What market realities or competitive threats or internal constraints does this strategy ignore? (Now is August 2025)
What is the biggest risk in this plan?
Role context: You specialize in [YOUR INDUSTRY] and have guided companies through [RELEVANT CHALLENGES]. Be direct about potential failures, not diplomatic.Pro tip: Switch on “web search” so ChatGPT can get the current market context. Remember to attach internal context as well.
Technique 3: Start with your draft, brainstorm with AI, then iterate
Instead of asking AI to create documents from scratch, write a rough first draft yourself, then use AI as a brainstorming partner to strengthen it.
Context: Continuing with the same example as above. Say, you're a VP of Sales who is preparing your Q2 sales plan and need to stress-test your initial thinking.
Step 1 - Create a draft manually: Write a 1-2 page overview of your sales plan covering targets, customer segments, key products, channel split, etc.
Step 2 - Brainstorm prompt: Now go to ChatGPT or Claude, and use this prompt to brainstorm with it. Use the chat as a back-and-forth session. Let AI ask questions, point out gaps, suggest alternatives. Respond to its critiques or ask it to propose solutions. Continue for 10-15 exchanges.
You are my [CRO] with [x years] experience at companies like [xx, yy and zz]. I want to brainstorm my Q2 sales plan with you. Here's my draft: [PASTE DRAFT].
Let's have a strategic discussion and critique this plan.
What are the pros and cons of my approach?
What assumptions should I revisit?
What am I missing?
Any market, macro or competitor realities I am missing?Pro tip: For the last line in the above prompt to work properly, remember to switch on “web search”.
Step 3 - Final output: Now in the same chat as Step-2, use this prompt:
Based on our discussion, rewrite the sales plan incorporating the improvements we identified.
Use this structure: [YOUR FORMAT].
Add an executive summary at the top and key metrics/assumptions at the bottom.
Retain my writing style and tone of voice as in my draft. This conversational approach produces much stronger proposals than single prompts because AI excels at critiquing existing work and identifying blind spots through dialogue.
Final words
If you made it so far, kudos! Apply the above two-prompt strategies for high-stakes decisions: strategic planning, budget allocation, competitive moves, and resource planning.
Single prompts work fine for factual questions or creative tasks. For anything which is your key deliverable for your quarter, half-year or year, you’d be better off using multiple prompts like we saw in the previous section.
We’d love to hear your thoughts in the comments. Until next time!